# ZAB的体系结构 - ZooKeeper原子广播协议
ZAB协议的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper 是通过ZAB协议来保证分布式系统数据最终一致性。
# 定义
leader和follower(s)-- 在ZooKeeper集群中,一个节点是leader角色,其余的是follower(s)角色。leader负责接收所有来自客户端的状态变更(写请求), 并将这些变更复制到leader或者follower(s)上。读请求在所有follower(s)和leader之间进行负载均衡;transactions-- 事务,即Client状态变更, 它(们)会由leader传播到它的follower(s);e-- leader的epoch。epoch是由普通节点变为leader时,生成的一个整数。它应该大于任何先前leader的epoch;c-- 一个由leader生成的序数,从0开始,向上增加。它和epoch一起被用作对不断到来的Client(s)状态改变/事务进行排序;F.history--follower的history队列。用于确保到达事务,按照它们到达的先后顺序被提交;outstanding transactions--F.history中序号小于当前COMMIT序号的事务集合。
# ZAB要求
- 复制保证
- 可靠递送 -- 如果一个事务M被一个服务器提交,它最后也会被所有服务器提交。
- 绝对顺序 -- 如果一个服务器提交的事务A先于事务B, 那么对于所有服务器,A都将先于B被提交。
- 因果顺序 -- 如果事务B发送的时间,是在B的发送者提交事务A之后,A必须是排在B之前。如果在发送B之后,某个发送者发出C ,那么C必须排在B之后。
- 只要过半的节点是正常的,事务就会被复制。
- 在事务复制期间,因down机错过的失败节点,恢复运行时应能再次获得。
# ZAB 实现
客户端可以从任何ZooKeeper节点发起读操作,对任何ZooKeeper节点执行写操作,状态变更会被先转发到leader节点。
ZooKeeper使用一种二阶段提交协议的变体,复制事务到follower(s)。当leader接收到来自某个客户端的状态更新时,它用序数c(32位)和leader epoch e(32位)生成一个事务(Zxid),并将其发送给所有follower(s)。
follower接收后,会将transactions添加到它的F.history队列中,并向leader回送ACK。当leader收到过半的的ACK时,它就会发出事务COMMIT。接收到提交的follower(s)就会COMMIT该事务,除非c值大于它F.history队列里的所用序号。这时,它会先等待接收先前事务(outstanding transaction(s))的提交操作,然后再执行该提交。
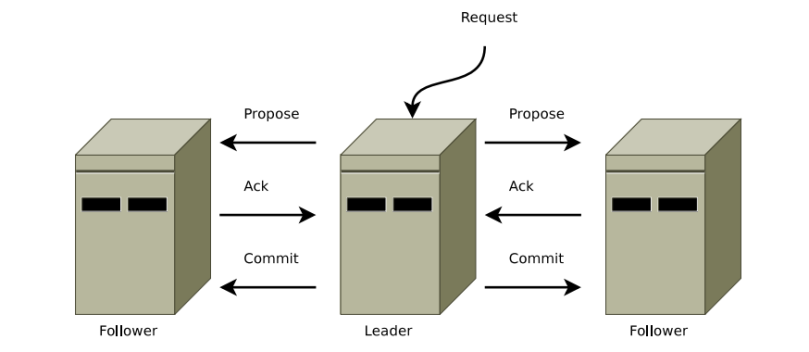
一旦leader崩溃,节点间会执行一个崩溃恢复协议,以确保以下两点:
- 恢复正常服务之前,节点间对共同状态的一致性达成共识;
- 找出一个新
leader来广播状态更新。一个节点要行使leader角色,必须获得法定人数(quorum)数量的节点支持。现实中,由于存在节点的崩溃、恢复往复;一段时间里,可能出现多位leader的更迭,甚至是同一节点多次成为leader的情形。
节点的生命周期:每个节点要么一次执行这个协议的一个完整循环;要么循环被突然中断,回到Phase 0, 再开始一个新的循环。
- Phase 0 -- leader选举
- Phase 1 -- 发现
- Phase 2 -- 同步
- Phase 3 -- 广播
注:
Phase 1 和 Phase 2,对于确保所有节点上状态的一致性很重要,特别是在节点从崩溃恢复时。
# Phase 0 -- leader选举
节点在该阶段运行初始化,状态为election。leader选举协议不必多特别,只要可结束、高概率,能选出一个可用节点,选举节点数达到法定人数(quorum)数量就行。leader选举算法结束后,节点会将它的选举结果保存到本地内存。
大致为:
如果节点p投票给p0, 那么p0就称为p的预期leader;如果节点投票给它自己,它的状态应设为leading,否则就设为following。顺便提一下,只有到达Phase 3的开始,这里选出的预期leader才可能变成真正的leader,并成为主处理节点。
# Phase 1 -- 发现
在这个阶段,follower(s)和它们的预期leader保持通讯,以便leader能够收集有关follower(s)最近接受的事务信息。这个阶段的目的,是为了在**法定数量(quorum)**节点内,发现尽可能多的已接受事务更新序号,以便创建一个新的epoch,以防先前的leader再提交新的事务。
理论上,具有法定人数(quorum)数量的follower(s)都拥有前任leader所有已接受状态变更的信息,于是在当前法定节点数(quorum)中,至少有一个follower,在F.history队列中拥有前任leader所有已接受的状态变更。这就意味着,这位新leader同样可以获得这些信息。
# Phase 2 -- 同步
同步阶段对该协议的发现阶段做出总结,即leader将用发现阶段获得的变更历史,对集群节点进行同步操作。leader会和follower(s)进行通信,并从自己F.history队列里发出事务。如果follower(s)的F.history滞后于leader,follower(s)就会回复ACK; 当leader看到来自法定节点数(quorum)的ACK,它就会发出提交信息给它们。此时,leader角色真正成立,不再是预期leader了。
# Phase 3 -- 广播
现在开始,如果没有节点发生崩溃,它们将永远呆在该阶段,收到ZooKeeper Client发出的写请求,就执行事务广播。
注:
对于失败检测,ZAB采用的是在leader和follower(s)间周期性的发送心跳(heartbeat)信息。如果leader在规定时间内,没有收到法定数量(quorum)节点的心跳,它就会放弃领导权,并转到选举状态(Phase 0);而如果follower超时未收到来自leader的心跳(heartbeat)也会转入leader选举阶段。
← 概述 Watch 机制 🔨 →