# 倒排索引
# 倒排索引的数据结构
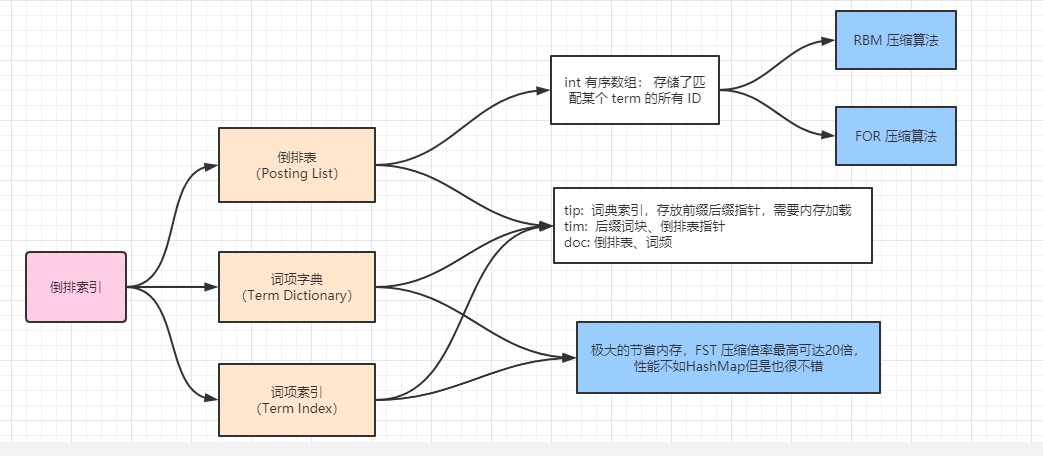
倒排表(Posting List),词项字典(Term Dictionary),词项索引(Term Index)
倒排索引(Inverted Index)也叫反向索引,是通过Value去找Key,跟我们传统意义的根据Key找Value不太一样。
倒排索引的数据结构如下图:
举个例子:
假设有一个user表,它有四个字段:分别是name gender age address。关系型数据库结构如下:
| ID | name | gender | age | address |
|---|---|---|---|---|
| 1 | 张三 | 1 | 22 | 上海市虹口区 |
| 2 | 李四 | 2 | 25 | 安徽省合肥市 |
| 3 | 王五 | 1 | 21 | 安徽省宣城市 |
- 词项(Term):一段文本进过分析器分析以后,就会输出一串
Term。 - 词项字典(Term Dictionary):Term(词项)的集合
- 词项索引(Term Index):为了更快的找到某个词项,为
Term建立索引 - 倒排表(Posting List):倒排表记录了出现过每个词项(Term)的所有文档列表以及词项出现在该文档中的位置信息,每条记录称为倒排项(Posting)。 根据倒排表,即可获知哪些文档包含某个词项。(实际的倒排表中并不只是存放文档ID这么简单,还有一些其他的信息,比如:词频,偏移量等)
PS
如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引。
我们知道,每个文档有一个ID,如果插入的时候没有指定的话,Elasticsearch会自动生成一个,上面的例子,Elasticsearch建立的索引大致如下:
# Name 倒排索引
| Term | Posting List |
|---|---|
| 张三 | 1 |
| 李四 | 2 |
| 王五 | 3 |
# Age 倒排索引
| Term | Posting List |
|---|---|
| 22 | 1 |
| 25 | 2 |
| 21 | 3 |
# Gender 倒排索引
| Term | Posting List |
|---|---|
| 1 | [1,3] |
| 2 | 2 |
# Address 倒排索引
| Term | Posting List |
|---|---|
| 上海市 | 1 |
| 虹口区 | 1 |
| 安徽省 | [2,3] |
| 合肥市 | 2 |
| 宣城市 | 3 |
Elasticsearch分别为每个字段都建立了一个倒排索引。比如,在上面“张三”、“安徽省”、22 这些都是Term,而[2,3]就是Posting List。Posting List就是一个数组,存储了所有符合某个Term的文档ID。
只要知道文档ID,就能快速找到文档。那么要怎样通过我们给定的关键词快速找到这个Term呢?
这里就会引出接下来的两个概念,Term Dictionary和Term Index(可以把Term Index和Term Dictionary看成一步,就是找Term)。
为了查找Term方便,Elasticsearch把所有的Term都排序了,且是二分法查找的。Term Index为了优化Term Dictionary,减少磁盘上的寻址开销。
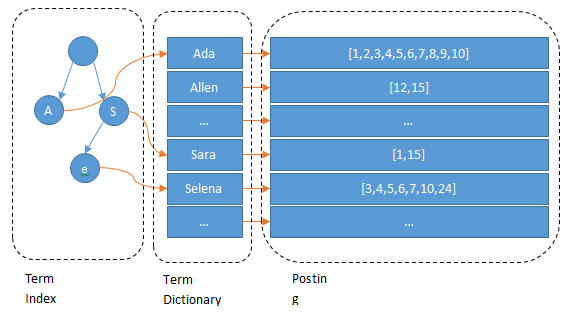
这就是三者的关系,是一张很经典的图了,Term Index就存了一些前缀和映射关系,这样可以大大减少磁盘的随机读次数了。
# FOR 压缩算法
适合稠密的数组
bit(比特) byte(字节),一个byte等于8个bit。磁盘存储最小的单位是byte。
# RBM 压缩算法
适合稀疏的数组
Container
# 字典树
# FST
FST(有限状态机),压缩Term Index。
参考文档