# Redis大key多key拆分方案
# 背景
在项目的Redis实际业务中,当使用Set存储过多的元素,就会形成Redis大key的情况
在阿里云 Redis 的开发规范 (opens new window), 对value设计有以下建议:
- 1)【强制】:拒绝 bigkey(防止网卡流量、慢查询) string 类型控制在 10KB 以内,hash、list、set、zset 元素个数不要超过 5000。
反例:一个包含 200 万个元素的 list。
非字符串的 bigkey,不要使用 del 删除,使用 hscan、sscan、zscan 方式渐进式删除,同时要注意防止 bigkey 过期时间自动删除问题 (例如一个 200 万的 zset 设置 1 小时过期,会触发 del 操作,造成阻塞,而且该操作不会不出现在慢查询中 (latency 可查)),查找方法和删除方法
# value中存储过多元素的解决方案
类似我们需要在Redis的Set存储一个学生ID的大集合场景
可以将这些元素作如下的分拆:
- 固定一个桶的数量,比如 5000, 每次存取的时候,先在本地计算field的hash值,模除 5000, 确定了该field落在哪个key上
- 那么根据学生ID模除 5000,确定该学生落在哪个key上
- 为了方便获取所有的学生ID,那么维护一个key来存储大纲学生key的集合(存学生ID模除 5000的值)
下图简要说明是怎么设计实现的:
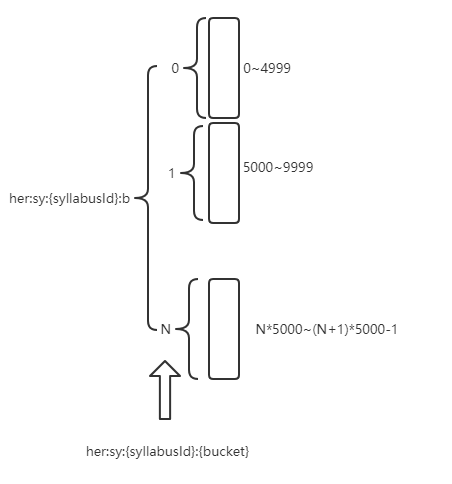
- 定义每个key为一个桶,那么这个桶
bucket=学生ID模除5000 - 为了快速查询所有桶,把桶的序号存储在
zc:m:bkey的set集合中
- 不适合的场景
如果要保证 SPOP 的数据的确是集合中的一个随机元素,这个就需要一些附加的属性,或者是在key的拼接上做一些工作