# 索引
本文是基于 InnoDB 存储引擎。
索引(B+树索引)的本质就是B+树在数据库中的实现。
B+树索引可以分为聚集索引(clustered index)和非聚集索引(secondary index),但是不管是聚集索引还是非聚集索引,其内部都是B+树的,即高度平衡的,叶子节点存放着所有的数据。
聚集索引和非聚集索引的区别是:叶子节点存放的是否是一整行的信息。
# 聚集索引
也叫
主键索引
聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。一个表不可能有两个地方存放数据,所以一个表只能有一个聚集索引。
InnoDB表中聚集索引的索引列就是主键,所以聚集索引也叫主键索引。
# 非聚集索引
也叫
辅助索引或二级索引或普通索引
辅助索引叶子节点的数据不是存储实际的数据,而是主键的值(或者叫做聚集索引键、bookmark)。要想拿到实际的数据需要再通过主键索引找到对应的行记录然后才能拿到实际的数据,这个过程称为回表。
如果查询语句可以从非聚集索引(包括联合索引)中获取到所有需要的列,这时不需要再通过主键索引找到对应的行记录,这种情况称为覆盖索引(索引覆盖)。
# Cardinality 值
基数值越大越好,越趋近总记录数越好。
不是所有的查询条件出现的列都需要添加索引。对于什么时候添加B+树索引。一般的经验是,在访问表中很少一部分时使用B+树索引才有意义。对于性别字段、地区字段、类型字段,它们可取值范围很小,称为低选择性。
怎样查看索引是否有高选择性?可以通过以下SQL查询结果中的列Cardinality来观察。
mysql>SHOW INDEX FROM `TABLE_NAME`
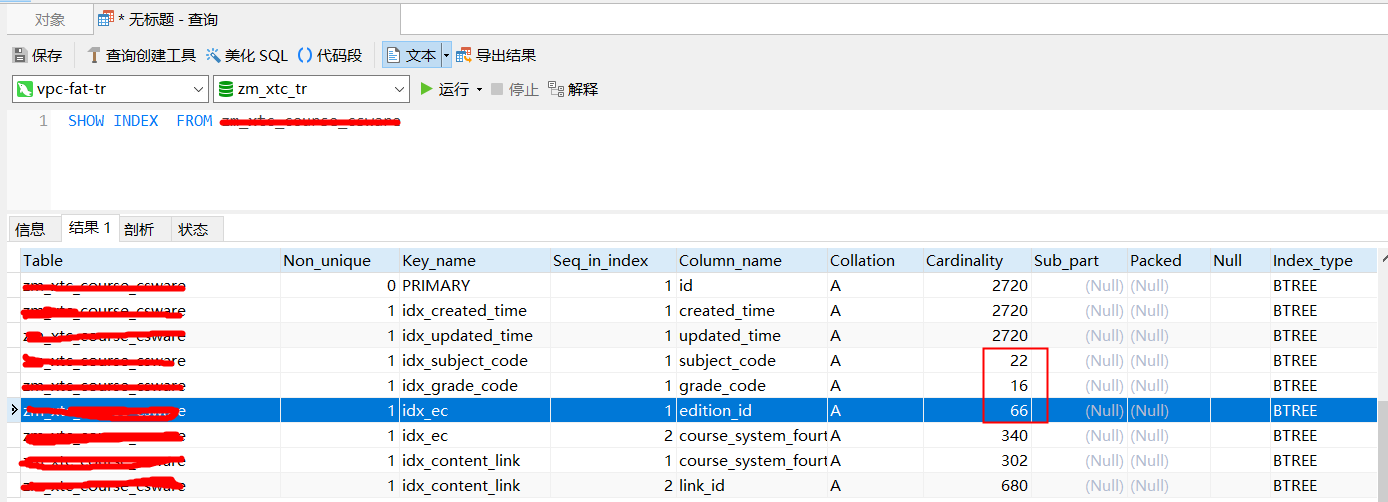
Cardinality值非常关键,表示索引中不重复记录数量的预估值。同时需要注意的是,Cardinality一个预估值,而不是一个准确值,基本上用户也不可能得到一个准确的值。
# B+树索引的使用:联合索引
联合索引是指对表上的多个列进行索引。联合索引也是B+树索引,不同的是联合索引的键值的数量不是1,而是大于等于2。
联合索引中列的顺序很重要。InnoDB首先根据联合索引中最左边的、也就是第一列进行排序,在第一列排序的基础上,再对联合索引中后面的第二列进行排序,依此类推。
所以如果想使用联合索引的第n列,查询条件中必须包括联合索引前面的第1列到第n-1列的查询信息。如(group, score),可能出现以下排序(1, 46), (1,58), (2,23), (2,96), (3,25), (3,67)。
如果要使用该索引的score,查询条件中必须包含group,如where group = 2 and score = 96,InnoDB通过group查询后,再通过score查询,这个规则称为最左前缀匹配原则(最左匹配原则)。
为什么最左匹配?
- 因为mysql创建联合索引时,首先会对最左边字段排序,也就是第一个字段,然后再在保证第一个字段有序的情况下,再排序第二个字段,以此类推。
- 举例:可以把联合索引看成“电话簿”,姓名作为联合索引,姓是第一列,名是第二列,当查找人名时,是先确定这个人姓再根据名确定人。只有名没有姓就查不到。
# B+树索引的使用:覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为覆盖索引。即只需扫描索引而无须回表。
应用场景:全模糊查询使用索引(索引扫描不回表)
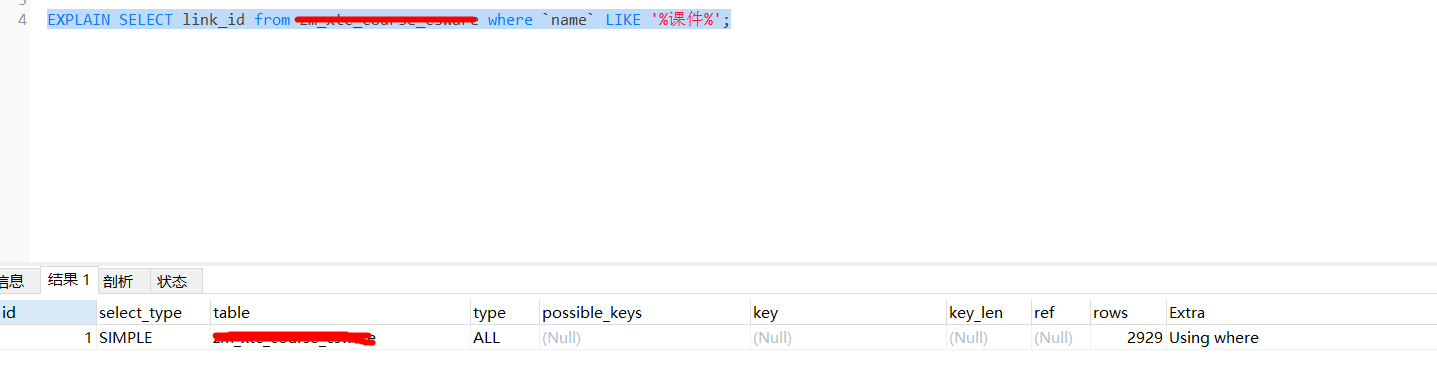 从执行计划看到
从执行计划看到 type=ALL,Extra=Using where 走的是全表扫描,索引失效。
利用覆盖索引的特性,改下后的SQL如下;
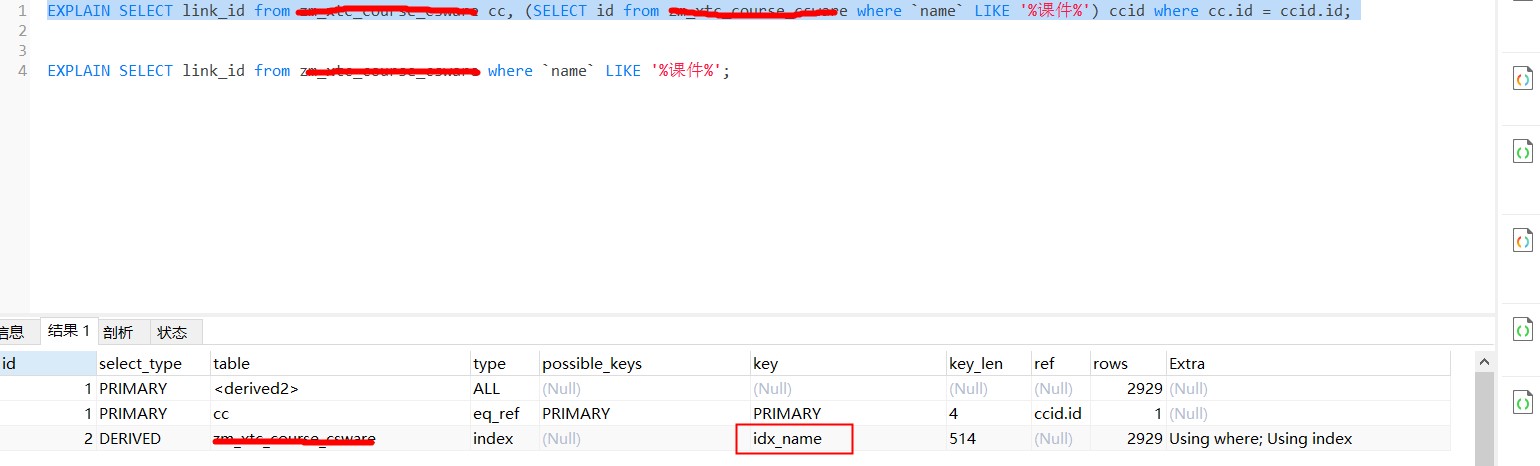 从执行计划看,走了索引
从执行计划看,走了索引idx_name,不需要回表访问数据,可以利用Using where; Using index这种索引扫描不回表的方式减少资源开销来提升性能。