# kafka
特别提示
本文基于 kafka 2.5.0 介绍实际开发中常用的一些概念,非常详细的介绍,请参考官方文档 (opens new window)
# 术语
- Broker : kafka 集群包含一个或多个服务器,这种服务器被称为 broker
- Topic : 每条发布到 kafka 集群的消息都有一个类别,这个类别被称为 Topic(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据,不必关心数据存于何处)
- Partition : 是物理上的概念,每个 Topic 包含一个或多个 Partition.
- Producer : 负责发布消息到 kafka broker
- Consumer : 消息消费者,向 kafka broker 读取消息的客户端。
- Consumer Group : 每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)
Kafka的记录(消息)
每条记录都包含 一个 key, 一个 value, 一个 timestamp.
# kafka 拓扑结构
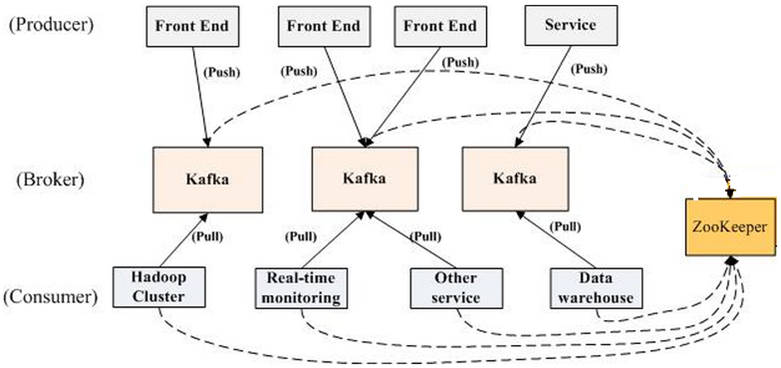
如上图所示,一个典型的 kafka 集群中包含:
- 若干 Producer(可以是 web 前端产生的 Page View,或者是服务器日志,系统 CPU、Memory 等)
- 若干 broker(kafka 支持水平扩展,一般 broker 数量越多,集群吞吐率越高)
- 若干 Consumer Group
- 一个 Zookeeper 集群
kafka 通过 Zookeeper 管理集群配置,选举 leader,以及在 Consumer Group 发生变化时进行 rebalance。
Producer 使用 push 模式将消息发布到 broker,Consumer 使用 pull 模式从 broker 订阅并消费消息。
# Topics and Logs
(阿里云)Topic的取值:
- 只能包含字母、数字、下划线(_)和短划线(-)
- 长度限制为3~64字符
- Topic名称一旦创建,将无法修改
kafka 中的 Topic 始终是多用户的;也就是说,一个主题可以有零个,一个或多个消费者来订阅或写入该 Topic 的数据。
对于每个 Topic ,Kafka集群 都会维护一个分区日志,如下所示:
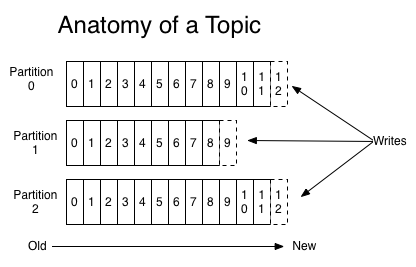
每个 Partition 都是有序的, 不变的记录队列, 新提交的记录顺序追加到这个队列中。 每个 Partition 中的记录都会分配一个 offset (偏移量) 的顺序 ID ,该 ID 唯一地标识 Partition 中的每个记录。
Kafka集群根据配置持久保存所有已发布的记录(无论是否已使用它们)。例如:如果保留策略设置为两天,则在发布记录后的两天内,该记录都可被使用,之后将被丢弃以释放空间。Kafka的性能相对于数据大小实际上是不变的,因此长时间存储数据不是问题。
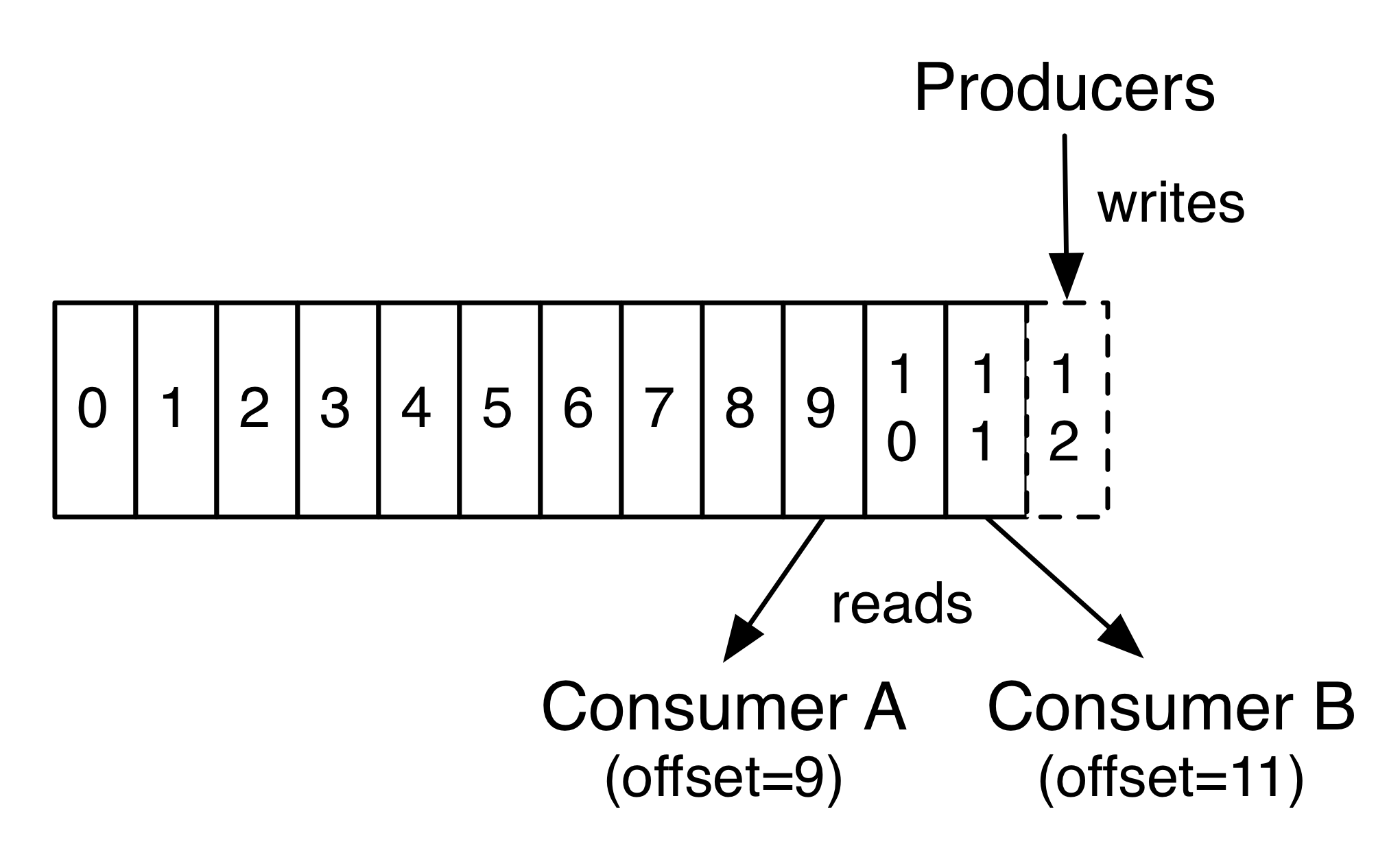
实际上,基于每个 Consumer 保留的唯一元数据是该 Consumer 在记录中的 offset(偏移量或位置)。此 offset 由使用者控制:通常使用者在读取记录时会顺序的移动其 offset,但实际上,由于位置是有使用者控制的,因此它可以按喜欢的任何顺序使用记录。例如,使用者重置到较早的 offset 重新处理过去的数据,或者跳到最近的记录并从“现在”开始使用。
Kafka中的Topic为什么要进行分区?
为了性能考虑,方便水平扩展
Kafka 中的Topic是逻辑概念,而Partition是物理概念,对用户是透明的。用户只需指定消息的Topic即可生产或消费数据,不必关心数据存于何处。
如果Topic内的消息只能存在一个Broker,那么Broker就会成为瓶颈,无法做到水平扩展。所以把Topic内的消息分布到集群就是并且引入Partition就是为了解决水平扩展问题的。
从上我们知道每个 Partition 都是有序的, 不变的记录队列,新提交的记录顺序追加到这个队列中。在物理上,每个 Partition 对应一个文件夹。一个Broker上可以存放多个Partition。 这样 Producer 可以将数据发送给多个Broker上的多个Partition,Consumer也可以并行从多个Broker上的不同Partition上读数据,实现了水平扩展。
# Producers
Producer 将数据发布到指定的主题。你可以简单地为负载均衡而采取循环方式完成此操作,也可以根据某些规则(例如基于记录的KEY)来完成此操作。
# Consumers 🎉
Consumer使用group name 标记自己, 并且发布到Topic的每条记录都会传递到每个订阅Consumer Group中的一个 Consumer 实例。
如果所有的 Consumer 实例拥有相同的Consumer Group,那么记录会均衡的分配到 Consumer 实例中。
如果所有的 Consumer 实例拥有不同的Consumer Group,那么每天记录都会广播到所有的 Consumer进程中。
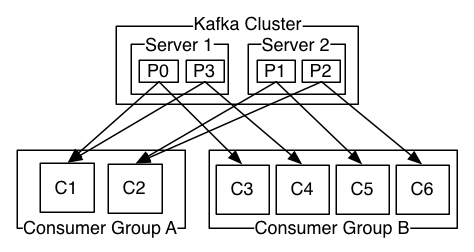
如上图所示:一个Kafka集群拥有两台服务器、4个Partition(P0-P3)、2个Consumer Group,Consumer Group A有2个消费实例,Consumer Group A有4个消费实例,
总结
同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。
在Kafka中,Consumer Rebalance 算法如下:
- 将目标
topic下的所有partition排序,存于PT - 对某Consumer Group下所有
Consumer排序,存于CG,第i个consumer记为Ci N = size(PT)/size(CG),向上取整- 解除
Ci对原来分配的partition的消费权(i从0开始) - 将第
i*N到(i+1)*N-1个partition分配给Ci
例如:
- 有4个partition,2个consumer,则会把p0~p1分配给c0,p2~p3分配给c1;
- 有4个partition,3个consumer,则会把p0~p1分配给c0,p2~p3分配给c1,c2未分配;
- 有4个partition,4个consumer,则会把p0分配给c0,p1分配给c1,p2分配给c2,p3分配给c3;
Consumer rebalance 的控制策略是由每一个 Consumer 通过 Zookeeper 完成的。具体的控制方式如下:
- 在
/consumers/[consumer-group]/下注册id - 设置对
/consumers/[consumer-group]的watcher - 设置对
/brokers/ids的watcher zk下设置watcher的路径节点更改,触发Consumer rebalance
羊群效应理论
任何broker或者consumer的增减都会触发所有的consumer的rebalance
Kafka 仅仅提供 一个Partition 内的记录顺序,而不能提供在同一 Topic下不同 Partition的顺序。当你需要同一 Topic的记录是顺序的,则可以使用一个Partition的Topic来实现:
- 发送消息到只有一个Partition的Topic
- 发送消息指定Partition
- 发送消息的KEY相同(消息KEY相同,那么消息提交的到Partition是相同的)
# Kafka为什么高吞吐量
- 顺序读写
- 零拷贝
- DMA(Direct Memory Access)